Local AI Operating Systems: Who Owns the System You Run On?
Local AI operating systems let mid-market firms run AI on infrastructure they own. The real case is ownership, cost control and IP, not just compliance.
Most coverage of local AI starts with a regulator holding a clipboard. That framing is too narrow, and it lets the majority of businesses off the hook. The real question is not "are you allowed to send this data to a third party." It is simpler and harder: who owns the AI system your business is starting to depend on, and what happens to you when the owner changes the terms.
For a growing number of mid-market firms, the honest answer to that question is pushing AI workloads back onto infrastructure they control. Not as a retreat from the cloud, and not because a compliance officer made them. Because the economics, the available models, and the strategic risk have all moved at once.
This is what a local AI operating system is, what it is genuinely good for, and where the hype falls apart.
In short: a local AI operating system is a complete AI environment that runs on infrastructure you own or directly control, so your business data is processed in-house rather than sent to an external provider. The durable case for it is ownership, predictable cost and protection of intellectual property, with compliance as a bonus rather than the headline.
What is a local AI operating system?
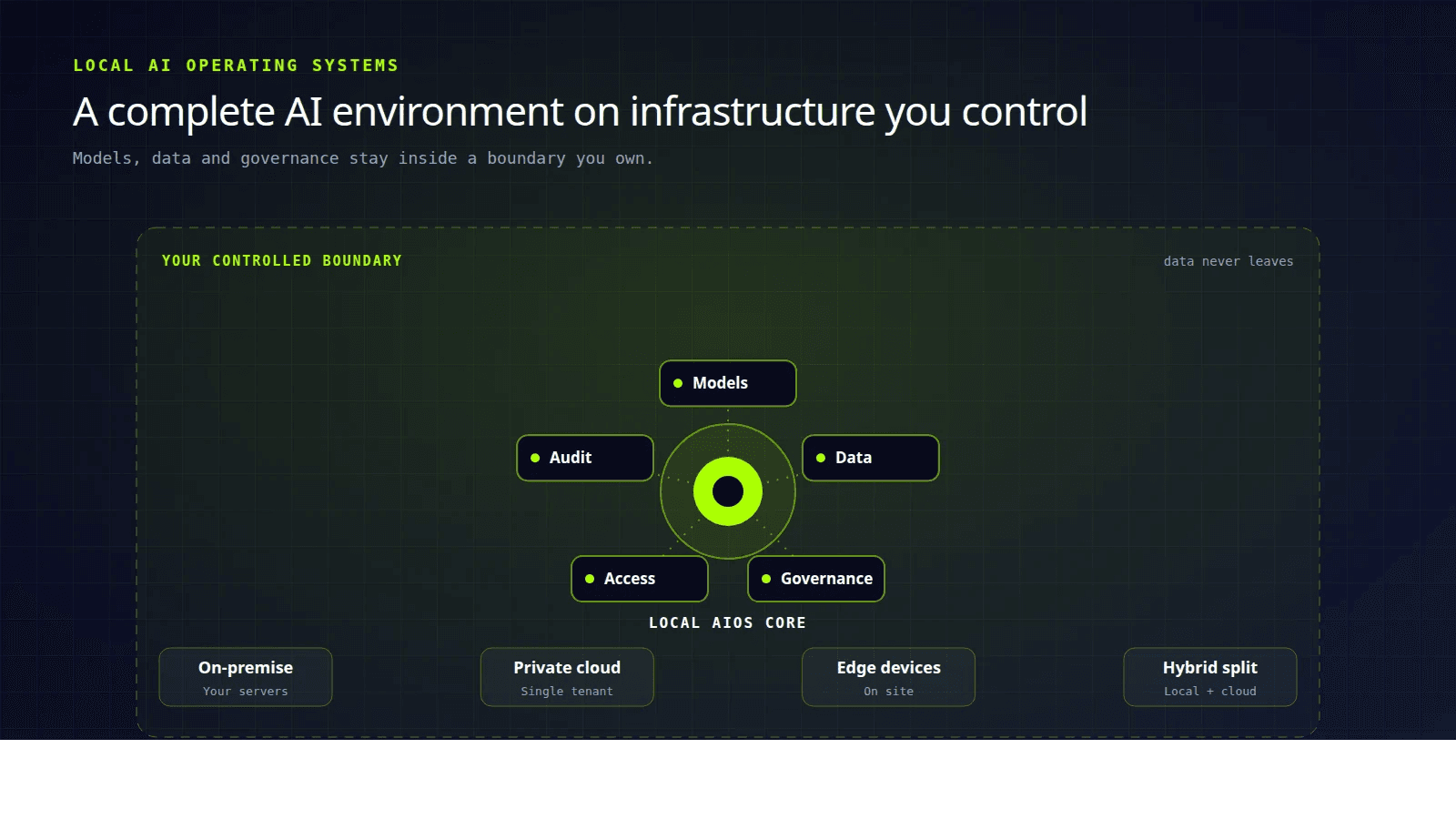
A local AI operating system (a local AIOS) is a complete AI operating environment that runs on infrastructure you own or directly control, rather than on a provider's shared platform.
Think of it as the locally hosted form of an AI operating system, the same orchestration of models, data and workflows, but kept inside a boundary you own.
In practice that means one of four setups:
- On-premise servers sitting in your own building or data centre.
- Private cloud instances running in a single-tenant environment with no shared compute.
- Edge devices deployed at specific sites, such as a branch, a shop floor or a clinic.
- Hybrid arrangements that keep sensitive or high-volume work local and send everything else to the cloud.
The defining property is data locality. With a local AIOS, your business data is processed inside an environment you control. It is not sent to an external model provider, retained in their systems, or absorbed into a shared model that other organisations also use. That is the whole point, and everything below follows from it.
A few terms worth pinning down:
- Local AIOS: an AI operating environment hosted on hardware you own or control, where the data never leaves your perimeter.
- Self-hosted LLM: a large language model you run on your own hardware, rather than calling through a provider's API.
- Private AI infrastructure: the compute, storage and networking you own, or rent single-tenant, to run AI in isolation from shared platforms.
Why mid-market firms are bringing AI in-house
The compliance argument is real, but it is the last reason on this list, not the first. Here are the four that apply whether or not a regulator is involved.
1. You keep control of your data
The data your teams are feeding into AI tools is getting more sensitive, fast. Cyberhaven's 2025 analysis of real enterprise activity found that 34.8% of the corporate data being pasted into AI tools is now sensitive, up from 10.7% two years earlier. That is your customer records, pricing, contracts and internal documents leaving the building.
This is why data privacy keeps topping the list of AI worries. In Deloitte's enterprise survey, roughly two in five professionals named data privacy their single biggest ethical concern about generative AI, nearly double the share who said so in 2023. A local AIOS does not manage that exposure. It removes it, because the data never leaves your environment in the first place.
2. Your intellectual property stays yours
Your processes, your customer relationships and your accumulated operational knowledge are assets. Run AI against them on someone else’s platform and you are, at best, trusting a contract to keep those assets out of a shared model ecosystem. Run it locally and there is no third party to trust, because there is no third party. For a firm whose edge is how it does the work, that distinction is the difference between a tool and a leak.
3. Your costs become predictable
This is the reason most people underrate, and it is getting stronger. Cloud AI pricing is not a law of nature. Stanford's 2026 AI Index reports global corporate AI investment hit $581.7 billion in 2025, up about 130% in a year, and warns that the binding constraint now is compute capacity, not model capability. Translation: the assumption that per-token cloud prices only ever fall is exactly the assumption to stop making. A local deployment converts an unpredictable, usage-metered, vendor-controlled operating cost into a fixed capital cost on hardware you own. For high-volume, repetitive AI work, that maths often favours local well before it favours an API bill that grows with every successful use case.
4. You stop depending on a platform you do not control
When your operations run on an external model, you inherit every decision that provider makes: price changes, deprecated models, rate limits, outages, terms-of-service revisions, and the day they retire the exact model your workflow was tuned around. Owning the stack means none of those are someone else’s call. Your AI does not degrade because another customer is hammering the same shared platform, and it does not disappear because a roadmap changed.
And yes, if you happen to be in a regulated sector, a local AIOS also collapses a whole category of contractual and cross-border risk into a technical control you can demonstrate. Gartner projects that more than 40% of AI-related data breaches will involve improper cross-border use of generative AI by 2027. Keeping the data in one place you govern is a clean answer to that. But notice this is the bonus, not the headline.
The economics changed, and that is the real story
The reason this conversation is happening now, rather than in 2023, is that running capable models on your own hardware stopped being exotic and started being boring. The numbers are the argument.
- Inference got radically cheaper. Stanford's AI Index found the cost of running a model at GPT-3.5 level (about 64.8% on MMLU) fell from roughly $20 per million tokens in late 2022 to about $0.07 by late 2024. That is a 280-fold drop in around eighteen months. The capability that used to justify a premium cloud contract is now cheap enough to host yourself.
- Open models all but caught up. The same Index measured the gap between the best open-weight and best closed models narrowing from 8% to 1.7% on some benchmarks in a single year. By the 2026 edition, the gap between the leading US model and the leading Chinese open-weight model had closed to 2.7% on the LMArena leaderboard. Open weights are no longer the compromise option.
- The hardware curve is on your side. The Index puts the annual decline in AI hardware cost at about 30%, with energy efficiency improving roughly 40% a year. The on-premise box that looks expensive today looks routine in two budget cycles.

Put together: the models you can self-host are now within a couple of percentage points of the frontier, and the cost of running them is collapsing. The case for sending everything to a third party is weaker than it has been at any point since this started.
What you can actually run locally in 2026
Not everything belongs on local hardware, and pretending otherwise is how projects fail. Here is the honest split.
Practical to run locally today:
- Small to mid-sized language models. Models in the 7B to 14B class, such as Mistral 7B, Qwen 2.5 7B or Llama 3.1 8B, run comfortably on a single modern GPU and handle the majority of everyday business tasks.
- Fine-tuned, domain-specific models. A smaller model trained on your own data will frequently beat a much larger general model on your specific task, at a fraction of the running cost.
- Embedding models for search and retrieval, vision models for document and image processing, and speech models for local transcription.
Better left in the cloud, at least for now:
- The very largest open models. Frontier-class open weights such as DeepSeek-V3, Qwen3-235B or Llama's 405B tier need serious multi-GPU hardware. Capable of being self-hosted, but rarely worth it for a mid-market firm.
- Model training. Training and heavy fine-tuning are compute-hungry and bursty, which is exactly what cloud is good at.
- Fast-moving experimentation. When you are still deciding which model to use, renting is cheaper than buying.
A note on hardware, because the usual blog gets this wrong. Local inference runs on GPUs, almost always NVIDIA, increasingly AMD, with compact edge units such as NVIDIA Jetson for distributed sites. Google’s TPUs, despite appearing on every "local AI hardware" listicle, are a Google Cloud product. You cannot rack a TPU pod in your own server room, so do not budget for one.
What a local AIOS does not fix
If a vendor tells you local AI is all upside, end the meeting. The honest limitations:
- It is not "zero latency". Local removes the network round-trip, which matters for real-time and voice work. It does not make inference instant. The model still has to think.
- It is not free. You are trading a metered cloud bill for hardware, power, and the engineering time to run it. That trade pays off at volume and for sensitive workloads. It does not pay off for a team sending fifty prompts a day.
- It still needs governance. Local does not mean ungoverned. You still need access controls, model versioning, audit trails and a human-review path for consequential decisions. The infrastructure moved; the responsibility did not.
- It needs people who can run it. ONS data shows UK AI adoption is already a two-speed race: around 44% of large firms but closer to 26% of small firms, with overall business adoption near one in four by late 2025. The gap is rarely about wanting AI. It is about having the capability to deploy and operate it. Local raises that bar, which is precisely why most firms should not attempt it unaided.
The honest verdict: hybrid, with judgement about what goes where
The right answer for almost every mid-market firm is not local versus cloud. It is local and cloud, with a deliberate line between them.

Keep local: the sensitive data, the IP-critical processes, and the high-volume repetitive work where a fixed cost beats a metered one. Send to cloud: model training, experimentation, and occasional burst workloads where the latest frontier model genuinely earns its keep.
That is not a fence-sit. It is the configuration that gives you data control and predictable cost where it matters, without paying to reinvent infrastructure you can rent for the parts that do not.
How to decide what belongs local
A condensed version of how we approach this with clients:
- Map data sensitivity. Identify which workflows touch data you would not want leaving your control. Those are your local-first candidates.
- Quantify the volume. High-frequency, repetitive AI use is where local economics win. Map your actual usage, not your imagined usage.
- Right-size the hardware. Start with what those workloads need and scale into it. Over-provisioning on day one is the most common and most expensive mistake.
- Pick models to fit, not to impress. A well-tuned smaller model usually beats a larger general one on a specific task, and costs less to run.
- Build governance in from the start. Access, versioning, audit and escalation are part of the deployment, not an afterthought.
The point
Cloud AI is a good tool. It is not a good landlord. The moment AI stops being an experiment and starts being something your operations actually depend on, "who controls this" becomes a strategic question, not a technical footnote. Local AI operating systems exist so that the answer can be "we do".
For a lot of mid-market firms, the smart move is not to rip out the cloud. It is to draw a clear line, keep the data and the high-value work on infrastructure you own, and stop renting the foundations of your business by the token.
If you want to work out which side of that line your workloads belong on, that is exactly what we do. Learn more about our local AI integration services, or book a consultation and we will map it with you.
Sources
- Stanford HAI, AI Index Report 2025 and 2026 (inference cost, open vs closed gap, hardware cost decline, US-China gap, corporate AI investment).
- Office for National Statistics, Business Insights and Conditions Survey / Management and Expectations Survey, via University of Cambridge Bennett School analysis (UK adoption by firm size).
- Deloitte, State of Generative AI in the Enterprise (data privacy as top ethical concern).
- Cyberhaven Labs, 2025 AI Adoption and Risk Report (share of sensitive corporate data entering AI tools).
- Gartner projection on cross-border generative AI and data breaches by 2027.
Frequently asked questions
Is a local AI operating system only for regulated industries?+
No. Regulated firms have a compelled reason to go local, but the durable case (data control, IP protection, predictable cost and independence from a single provider) applies to any mid-market business running AI on data it cares about.
Is local AI cheaper than using a cloud API?+
It depends on volume. For low or occasional use, a cloud API is cheaper. For high-volume, repetitive workloads, a fixed-cost local deployment frequently wins, and it removes your exposure to cloud price changes.
Can open-weight models really compete with the likes of GPT and Claude?+
Much more than they used to. Stanford's AI Index measured the best open models closing to within roughly 2% of the best closed models on some benchmarks. For most business tasks, a self-hosted open model is now good enough.
Do I need a data centre to run local AI?+
No. Many local AIOS deployments run on a single GPU server or a private cloud instance. The scale should match the workload, not the ambition.